Guide de lemmatisation pour médiévistes
Table des matières
Contributeurs:
- Eliana Magnani
- Nicolas Perreaux
- Ariane Pinche
- Thibault Clérice
- Philippe Verkerk
Qu’est-ce que la lemmatisation?
La lemmatisation est le processus inverse de la flexion (déclinaison ou conjugaison). Cette dernière associe à un lemme (l’entrée d’un dictionnaire) toutes les formes fléchies qui en viennent. Il s’agira des formes déclinées pour un nom ou un adjectif et des formes conjuguées pour un verbe. La lemmatisation consiste donc en l’attribution d’un lemme à une forme fléchie. En plus de la flexion à proprement parler, on peut avoir des variations graphiques pour une même forme. On donne parfois le nom de “lexème” à une forme fléchie.
Dans le cas des langues flexionnelles et à forte variation graphique, comme celles employées dans l’Occident médiéval – le latin et les langues vernaculaires –, le développement de procédures de recherche formalisées et assistées informatiquement implique la lemmatisation des textes utilisés. Ce procédé – manuel, semi-automatisé ou automatisé –, n’est pas chose nouvelle, mais au cours des dernières années, plusieurs lemmatiseurs ou de paramètres pour la lemmatisation des langues médiévales ont été créés.
Pour quoi faire?
La lemmatisation s’inscrit dans le champ du traitement automatique du langage naturel (TAL/NPL). Il s’agit d’une opération nécessaire au préalable de différents types d’analyses de corpus textuels, de fouilles de texte/données (Text/Data mining), qu’elles soient d’ordre philologique ou historique.
Lemmatiser et annoter la morphosyntaxe d’un corpus permet par la suite de l’interroger pour le trier ou en vue d’analyses statistiques, opérations, souvent, aussi bien nécessaires au linguiste, qu’à l’éditeur scientifique qu’à l’historien. Par exemple à partir d’un corpus lemmatisé, il est facile de constituer un glossaire qui répertorie sous une même entrée toutes les variations graphiques d’un mot, en opérant un tri à partir du lemme de l’annotation qui, lui, est unique pour chaque mot du lexique.
L’analyse syntaxique d’un corpus étendu devient également possible pour détecter certains traits dialectaux. Par exemple, en ancien Picard, il arrive que le pronom personnel objet féminin se graphie le comme le pronom masculin, au lieu de la. L’annotation morphosyntaxique permet alors de calculer rapidement les statistiques d’apparition du phénomène dans les textes pour le dater ou déterminer les territoires où il est le plus fréquent. À l’échelle d’un texte, ces calculs permettent à l’éditeur de savoir si le phénomène est à la marge de son corpus ou pas, pour décider de corriger ou de conserver dans son édition la graphie en déterminant si elle relève du trait dialectal ou de l’erreur de copie.
Appliquée à un corpus textuel diachroniques, relatif à une entité spatiale précise (une région, par exemple) ou regroupant plusieurs de ces entités (l’ensemble des régions de l’Europe occidentale, par exemple), la lemmatisation permet de l’analyser du point de vue de la constitution et de l’évolution des champs sémantiques et de nourrir ainsi les interprétations historiques. La fréquence d’un mot, son association avec d’autres termes – les cooccurrences –, leur distribution dans la chronologie et dans différents espaces, sont autant d’éléments qui deviennent ainsi passibles d’être soumis à des observations empiriques et à des analyses statistiques. Il est possible alors d’évaluer les changements lexicaux et sémantiques en les corrélant à d’autres phénomènes historiques contemporains, de situer dans le temps et dans l’espace des innovations linguistiques et sémantiques inconnues ou encore de découvrir des associations lexicales inattendues.
Quels outils?
D’un point de vue technique, la lemmatisation automatique ou semi-automatique regroupe plusieurs opérations. Ces opérations interviennent après l’acquisition du ou des textes dans un format numérisé élémentaire (soit grâce à un fichier déjà disponible, soit grâce à une saisie manuelle, ou encore à un processus d’OCR/HTR). Les principales étapes de la lemmatisation proprement dite sont la tokenisation, c’est-à-dire le découpage du texte par lexème, au cours de laquelle le texte peut être pré-formaté selon les choix et besoins des concepteurs des outils (par exemple, nettoyage des caractères spéciaux, séparation d’enclitiques) ; l’étiquetage morphosyntaxique des formes (POS tagging = part-of-speech tagging) avec un jeux d’étiquettes très variable d’un outil à autre ; et le regroupement des formes sous le lemme correspondant. Plusieurs difficultés doivent être surmontées dans ce processus, notamment la désambiguïsation des homographes et les variations graphiques des formes.
Les outils actuels pour associer aux formes une étiquette (POS) correcte, se partagent en deux groupes principaux.
Les premiers utilisent des tagueurs probabilistes basés sur un lexique et des règles prédéfinies associés ou pas à des entraînements successifs qui améliorent la reconnaissance des formes et des lemmes (p. ex. TreeTagger avec les paramètres pour le latin médiéval OMNIA).
Les seconds sont basés sur les technologies plus récentes dites des « réseaux de neurones » (ou deep learning), des algorithmes qui, à partir d’un corpus pré-annoté (ou corpus d’entraînement) visent à apprendre l’application à créer les lemmes qui ne figurent pas dans le corpus d’entraînement, en fonction de leur représentation sémantique (les mots coocurrents) (p. ex. Pie, Hydra).
Dans les deux cas, un travail manuel en amont est nécessaire, l’établissement d’un lexique et des règles, ou l’annotation d’un corpus. En aval aussi l’intervention manuelle est nécessaire dans les deux cas pour corriger les corpus annotés par les lemmatiseurs
Par où commencer?
La lemmatisation comprend plusieurs étapes principales :
- L’acquisition du texte (ou du corpus de textes) numérisé est un préalable à la lemmatisation. Plusieurs cas de figure se présentent : utilisation de fichiers préexistants, saisie manuelle, ou encore recours aux méthodes automatiques de reconnaissance optique de caractères imprimés ou dactylographiés (OCR - Optical Character Recognition) ou d’écritures manuscrites (HTR - Handwritten Text Recognition).
- La préparation des fichiers consiste, d’une part, dans leur enregistrement avec l’encodage UTF-8 et en .TXT en général, et d’autre part, dans le processus de post correction, notamment pour les textes acquis par OCR ou HTR.
- Ce n’est pas obligatoirement lié à la lemmatisation, mais dans le cas de la constitution d’un corpus de textes, il faut penser à la préparation des métadonnées réunies en général dans un fichier .CSV. Les métadonnées concernent en particulier les noms de fichiers et les datations.
- La tokenisation consiste en la mise en forme souhaitée du texte (uniformisation des graphies, séparation ou pas des enclitiques, etc.), son découpage par lexème, un mot ou un signe de ponctuation par ligne. La tokenisation est optionnelle et peut être incluse ou pas dans les outils.
- La lemmatisation à proprement parler consiste en l’étiquetage morphosyntaxique des formes (POS-tagging = part-of-speech tagging), soit l’attribution d’un POS à chaque token (substantif, adjectif, préposition, conjonction, ponctuation, etc., associés ou pas au mode, au cas, au nombre). Les jeux d’étiquettes varient d’un outil à l’autre, 9 étiquettes pour le latin médiéval dans OMNIA, 91 étiquettes pour le latin classique dans Collatinus, par exemple. L’attribution du lemme à chaque forme intervient le plus souvent après l’attribution du POS.
- La recomposition des fichiers, avec les tokens, les lemmes et les métadonnées.
Voici l’exemple du traitement d’une inscription provenant de l’abbaye de Saint-Martin d’Autun, de la fin du IXe siècle, l’épitaphe de Letbaldus:
- Acquisition du texte numérisé à partir de l’édition océrisée disponible sur la plateforme Persée. Corpus des Inscriptions de la France Médiévale, vol. 19 : Jura, Nièvre, Saône-et-Loire, éd. R. Favreau, J. Michaud et B. Mora, Paris, CNRS Éditions, 1997, p. 62, n° 7 (https://www.persee.fr/doc/cifm_0000-0000_1997_cat_19_1).

- Le texte encodé en UTF-8, enregistré en .TXT, avec des élements de métadonnées simplifiées dans le titre du fichier (Date, Lieu, Référence de l’édition).
- Extrait d’une partie du fichier .CSV avec les métadonnées complètes du corpus d’inscriptions.
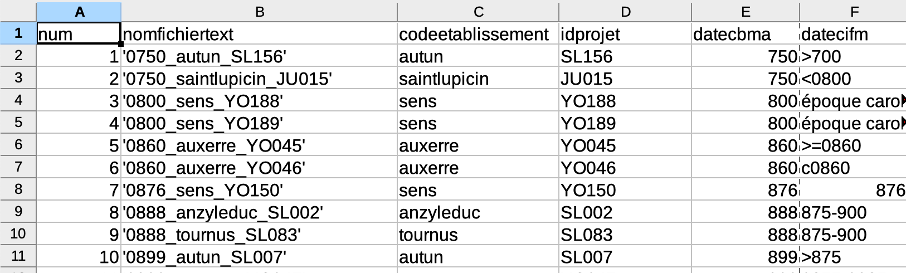
- Tokenisation (une ligne = un mot = un token), réalisée avec le tokenizer OMNIA (Renaud Alexandre), qui, entre autres, réalise aussi tout une série d’harmonisations du texte, comme le remplacement de « j » par « i », de « v » par « u », la séparation des enclitiques (aquarumque = aquarum + que), le remplacement les caractères accentués, la suppression des doubles espaces, entre autres (https://glossaria.eu/lemmatisation/#page-content).

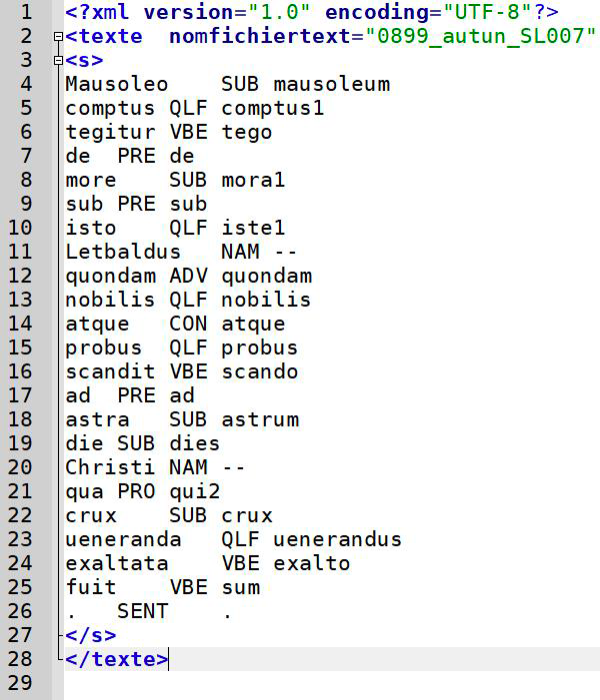
- Lemmatisation (POS-tagging), avec l’attribution d’un POS (part of speech) à chaque token, et reconstitution du fichier, avec l’ajout des métadonnées (ici, seulement le nom du fichier). Le fichier contient ainsi, pour chaque mot/token (première colonne), le POS (deuxième colonne) et le lemme (troisième colonne).
Bibliographie sélective
(dans l’ordre chronologique)
- Schmid H., “Part-of-Speech Tagging with Neural Networks”, Proceedings of the 15th International Conferenceon Computational Linguistics (COLING-94), 1944.
- Delatte L., Évrard É., “Un laboratoire d’analyse statistique des langues anciennes à l’Université de Liège”, L’Antiquité classique, 30-2, 1961, p. 429-444.
- Greeneand B., Rubin G., Automatic grammatical tagging of English.Technical report, Providence, 1971.
- Busa R., “The Annals of Humanities Computing : the Index thomisticus”, Computers and the Humanities, 14, 1980, p. 83-90.
- Guerreau A., “Pourquoi (et comment) l’historien doit-il compter les mots ?”, Histoire & Mesure, 4/1-2 (1989), p. 81-105. DOI: https://doi.org/10.3406/hism.1989.878
- Bon B., “OMNIA – Outils et Méthodes Numériques pour l’Interrogation et l’Analyse des textes médiolatins”, BUCEMA - Bulletin du centre d’études médiévales d’Auxerre, 13, 2009, p. 291-292. URL: http://journals.openedition.org/cem/11086
- Longrée D., Poudat C., “Variations langagières et annotation morphosyntaxique du latin classique”, TAL, 50 – n° 2/2009, Special issue on “Natural Language Processing and Ancient Languages”, p. 129-148.
- Bon B., “OMNIA: outils et méthodes numériques pour l’interrogation et l’analyse des textes médiolatins (2)”, BUCEMA - Bulletin du centre d’études médiévales d’Auxerre, 14, 2010, p. 251-252. URL: http://journals.openedition.org/cem/11566
- Longrée D., Philippart de Foy C., Purnelle G., “Structures phrastiques et analyse automatique des données morphosyntaxiques : le projet LatSynt”, in S. Bolasco, I. Chiari, L. Giuliano (eds), Statistical Analysis of Textual Data, Proceedings of 10th International Conference Journées d’Analyse statistique des Données Textuelles, 9-11 June 2010, Sapienza University of Rome, Rome, LED, p. 433-442.
- Longrée D., Poudat C., “New Ways of Lemmatizing and Tagging Classical and post-Classical Latin: the LATLEM project of the LASLA”, in P. Anreiter, M. Kienpointner (éd.), Proceedings of the 15th International Colloquium on Latin Linguistics, (Innsbrucker Beiträge zur Sprachwissenschaft), Innsbruck, 2010, p. 683-694.
- Longrée D., Philippart de Foy C., Purnelle G., “Subordinate clause boundaries and word order in Latin: the contribution of the L.A.S.L.A. syntactic parser project LatSynt”, in P. Anreiter, M. Kienpointner (éd.), Proceedings of the 15th International Colloquium on Latin Linguistics, (Innsbrucker Beiträge zur Sprachwissenschaft), Innsbruck, 2010, p. 673-681.
- Bon B., “OMNIA: outils et méthodes numériques pour l’interrogation et l’analyse des textes médiolatins (3)”, BUCEMA - Bulletin du centre d’études médiévales d’Auxerre, 15, 2011, p. 333-334. URL: http://journals.openedition.org/cem/12015.
- Guerreau A., “Textes anciens en série”, Bulletin du centre d’études médiévales d’Auxerre, BUCEMA, Collection CBMA, mis en ligne le 01 mars 2012. URL: https://doi.org/10.4000/cem.12177
- Ouvrard Y., Verkerk Ph., “Collatinus, un outil polymorphe pour l’étude du latin”, Archivum Latinitatis Medii Aevi, 72, 2014, p. 305-311.
- Perreaux N., L’écriture du monde. Dynamique, perception, catégorisation du mundus au moyen âge (VIIe - XIIIe siècles). Recherches à partir de bases de données numérisées, thèse de doctorat, Université de Bourgogne, Dijon, 2014. URL: https://shs.hal.science/tel-03084322
- Aouini M., “A NooJ Module for Named Entity Recognition in Middle French Texts”, in J. Monti, M. Silberztein, M. Monteleone, M. Pia di Buono (éd.), Formalising Natural Languages with Nooj 2014, Cambridge, 2015, p. 99-112.
- Eger S., vor der Brück T., Mehler A., “Lexicon-assisted tagging and lemmatization in Latin : A comparison of six taggers and two lemmatization methods”, Proceedings of the 9th SIGHUM Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities (LaTeCH), Beijing, 2015, p. 105–113.
- Horsmann T., Erbs N., Zesch T., “Fastor Accurate? A Comparative Evaluation of PoSTagging Models”, Proceedings of the Int. Conference of the German Society for Computational Linguistics and Language Technology, 2015, p.22-30.
- Eger S., Gleim R., Mehler A., “Lemmatization and Morphological Tagging in German and Latin: A comparison and a survey of the state-of-the-art”. Proceedings of the 10th International Conference on Language Resources and Evaluation, 2016. URL: http://www.lrec-conf.org/proceedings/lrec2016/pdf/656_Paper.pdf
- Kestemont M., De Gussem J., “Integrated Sequence Tagging for Medieval Latin Using Deep Representation Learning”, Journal of Data Mining and Digital Humanities, 2016. URL: https://hal.archives-ouvertes.fr/hal-01283083/
- Kestemont M., de Pauw G., van Nie R., Daelemans W., “Lemmatization for variation-rich languages using deep learning”, Digital Scholarship in the Humanities, 32-4, 2017, p. 797-815. DOI: https://doi.org/10.1093/llc/fqw034
- Gągała Ł., “Authorship Attribution with Neural Networks and Multiple Features : Notebook for PAN at CLEF 2018”, in L. Cappellato, N. Ferro, J.-Y. Nie, L. Soulier (éd.) Working Notes of CLEF 2018 - Conference and Labs of the Evaluation Forum. Avignon, France, September 10-14, 2018. URL: http://ceur-ws.org/Vol-2125/paper_146.pdf
- Manjavacas E., Kadar A., Kestemont M., “Improving Lemmatization of Non-Standard Languages with Joint Learning”, arXiv:1903.06939v1, 2019. URL: https://arxiv.org/format/1903.06939v1
- Manjavacas E., Kestemont M., emanjavacas/pie v0.1.3 (Version v0.1.3). Zenodo (2019, January 17). DOI: http://doi.org/10.5281/zenodo.2542537
- Clérice T., chartes/deucalion-model-lasla: LASLA Latin Lemmatizer - Alpha (Version 0.0.1). Zenodo (2019, February 1). DOI: http://doi.org/10.5281/zenodo.2554847
- Camps J.-B., Clérice T., Duval F., Ing L., Kanaoka N., Pinche A., “Corpus and Models for Lemmatisation and POS-tagging of Old French”, Journal of Data Mining and Digital Humanities, 2021. URL: https://shs.hal.science/halshs-03353125
- Holgado C., Lavrentiev A., Constant M., “Évaluation de méthodes et d’outils pour la lemmatisation automatique du français médiéval”, Traitement Automatique des Langues Naturelles, 2021, Lille, France, p.153-161. URL: https://hal.science/hal-03265897
- Clérice T., Détection d’isotopies par apprentissage profond: l’exemple de la sexualité en latin classique et tardif. Thèse de doctorat, Université Jean Moulin - Lyon 3, 2022. URL: https://www.theses.fr/s226893
- Clérice T., Jolivet V., Pilla J., “Building infrastructure for annotating medieval, classical and pre-orthographic languages: the Pyrrha ecosystem”, Digital Humanities, 2022. URL: https://hal.science/hal-03606756v1
- Sommerschield T., Assael Y., Pavlopoulos J., Stefanak V., Senior A., Dyer C., Bodel J., Prag J., Androutsopoulos I., de Freitas N., “Machine Learning for Ancient Languages: A Survey”, Computational Linguistics, 1-44 (2023). DOI: https://doi.org/10.1162/coli_a_00481